

Brian McMahon
International Union of Crystallography, 5 Abbey Square, Chester CH1 2HU, England
INTRODUCTION
The title of this lecture refers to portability and standardization. Portability - the ability to transfer information from one location to another - is of course a desirable facility. Standardization - the establishment of agreed terms for defining specific information - is the way to achieve this.
There are three types of portability we may consider, and we shall see how the various standards required to enable each type of portability can come together to provide a high-level specification for a data structure that allows a highly portable form of data transfer in our science of crystallography.
1. Portability of data structures for a specific application across machine architectures.
Computational packages for manipulation of experimental data, for crystal structure solution or for database management often require data to be stored in a compact form that may be efficiently handled by the computer hardware and operating system. It is efficient to pack data into machine words in such a way that memory is fully utilised; or it may be necessary to use highly machine-specific direct-access or indexed files.
But this can mean that a workfile or binary archive file cannot easily be transferred from one machine to another. Word sizes may differ between machines; byte ordering may differ within words; different record lengths may be supported. The same piece of code may write the same data structure to disc on two different computers, and yet the files so written are not directly transferable between machines. Worse, the same program running on the same machine may define different file structures according to the parameters with which it was compiled, and so portability is not even guaranteed at this level.
Data transfer between various implementations of the same package is therefore best achieved by dumping the data in a verbose, but relatively stable, interchange format. Text files essentially achieve this.
Plain-text format is, of course, not a universal standard. Different coding schemes exist to represent alphanumeric and other printable characters. ASCII and EBCDIC are the best known of these, and are together supported by the majority of computer installations, but other 8-bit, 7-bit and even 6-bit character codes exist; and international applications increasingly use multibyte or `wide' representations of non-Latin characters. Further, lines of text are delimited by different characters on different machines (NEWLINE on Unix, CR-LF on MS-DOS), and end-of-file markers differ.
Nevertheless, transportability of plain text is so important that most operating systems and communications utilities allow reliable interconversion between text files from different sources.
A further bonus of a plain-text data dump is that it is transmissable by electronic mail across most global computer networks. However, while alphanumeric characters are usually sent and received with total reliability, there are still major e-mail gateways which do not properly translate some punctuation characters between EBCDIC and ASCII sites.
2. Portability of data between similar applications
There are in crystallography very many computer programs which manipulate in different ways the same raw or processed data. In practice the trend has been to build integrated systems which pass data as it is processed from one subroutine or program to the next. However, there are still many occasions when it is desired to transfer the results of one program to a completely different application for further processing.
We have already seen arguments for transmitting such information in a plain-text representation, rather than a machine- and application-specific binary format. The next step is to ensure that the receiving program recognises the input data - that is, it is able to assign the correct values to its internal representation of the information it is processing. Traditionally, line-formatted records are used by Fortran programs to identify data. The disadvantage with this approach is that the generating and receiving programs need to have identical FORMAT commands and internal memory storage requirements to ensure that the data values are correctly transferred. While it is not particularly difficult to write FORMAT statements, each program must be carefully tailored to the requirements of others it needs to communicate with.
A better approach is to recognise the nature of an item of data dynamically, by reading an accompanying key. It is increasingly common in Fortran to write input routines that can handle data in `free format' (that is, data fields delimited by white space or other special characters, and not adhering to pre-ordained fixed lengths or types); and it is of course routine to adopt this approach in other languages, such as C.
A promising strategy is therefore to read in data as a sequence of (key, value) pairs, where the key is read to indicate to the program what symbolic name or array location should be allocated to the following value.
The success of this approach relies on the universal availability of known keys, so that the nature of the data is unambiguous. Here is a trivial example. If the string _cell_length_a is known to indicate the length of a crystal unit cell in angstrom units, then programs seeing this string can enter the accompanying value into the memory location referenced by the symbolic name A, CELLA, CELLEN(1), X032, or whatever the program author has chosen to indicate the cell a parameter.
Hence our second requirement for portability is that an archive file should contain data that is unambiguously retrievable through recognition of key patterns. The keys must then be defined in an external data structure, or `dictionary', that is available to the program author (or, in more sophisticated applications, to the program itself).
The definition of the keys (or `tags') that appear in the dictionary is an important and complex process, for it is necessary to abstract the essential elements of different data types. For instance, it is important that information on the labelling of atomic sites can be transported between applications; yet almost every program has its own idiosyncratic way of labelling atom positions. The key (or set of keys) chosen to represent the atom labelling must permit different programs to retain their own styles, yet must ensure that the relevant information is retained.
3. Portability of data across different applications
A corollary of the use of data keys within an archive file to identify the nature of the stored data is that the file may legitimately contain information not required by a program that reads it: any data that the program does not need is simply ignored. This allows the same file to be used for different applications, and so permits it to be a universal information transfer medium.
The draft specification we have implicitly drawn up in our discussions so far needs very little extension to allow it to act as the model for transferring crystallographic data between diverse applications. We need only permit the range of data types allowed within the file to include free-text fields of arbitrary length, and we have a recipe for a file structure that can contain all information that might be of interest to a crystallographer.
Such a file might well contain raw diffraction data. More usefully, it can contain structure factors, and so act as a near-primary repository of experimental information. This is essentially the role of deposit materials accompanying structural papers in Acta Crystallographica. Now, however, the structure factors are available in machine-readable form. The file may also contain: the results of crystallographic refinement; the experimental log; the derived geometry; connectivity data for the structure investigated; graphics commands or a graphical rendition of the structure; and the complete text of a descriptive paper. Because the numeric and other data are stored in tagged fields, the file may also be searched by database routines for specific information.
The file we are describing is intended to be the transporter of the information processed by the various applications, but is unlikely itself to be used as a work file. The target application will undoubtedly convert the input data into a compact native binary format for efficient processing.
A UNIVERSAL ARCHIVE FILE FOR CRYSTALLOGRAPHY
The IUCr has for a long time been keenly aware of the need for a universal data transfer protocol. In 1978, a standard file structure for crystallographic data was commissioned, and a candidate protocol was created in 1981. The file considered, known as SCFS (Standard Crystallographic File Structure), was intended to fulfil nine criteria:
1. It should be extendable to include all types of crystallographic data.
2. It should be compatible with current and future methods of data transmission.
3. It should be easy to program for both reading and writing.
4. It should not require re-read facilities, since these are not supported by all computers.
5. An output listing should be easy to read visually.
6. The only records that must be included are those required for data management (e.g. END). All other data are optional.
7. Provision should be made for the inclusion of derived data where required.
8. Comments may be included.
9. It is not primarily intended for manual editing (although it should be capable of being edited by hand).
The new file structure was described by Brown (1983), in an important paper that well explains the rationale behind the file structure chosen.
This initiative was important not least for its specification of data types that should be recognised across all applications.
However, some of the design choices made in this file structure have not proven popular over the years. In particular, criterion 3, that the file should be easy for a program to read and write, was taken to imply that fixed-format data records should be used. This meant that a precise format had to be specified for each type of data record expected, thus adding to the overall complexity of the standard and making extensions less easy to implement. Further, the criteria 5 (human readability) and 9 (facility for manual editing) were compromised by the rigid layout thus imposed.
A new study was therefore commissioned by the IUCr in 1987, and this resulted in the definition of the Crystallographic Information File (CIF), which has now been adopted by the Union as its official universal exchange file. The CIF format satisfies the same criteria addressed by the SCFS proposals, but with some changes in emphasis, and with significant changes in implementation.
Most notably, data items are not presented in fixed format, but are simply character strings delimited by white space and identified by a preceding key word, following the convention that we saw to be advantageous in our earlier discussion. For specific items of data that are not considered as members of an array, the key immediately precedes the value. For data arrays (which may be multi-dimensional), the data types are first declared after a `loop_' keyword, and the array elements are identified from their position in a following list.
Here are some examples of these ideas in practice. Figure 1 shows part of a CIF that contains information about the crystal unit cell.
_cell_length_a 8.709(2)
_cell_length_b 8.934(1)
_cell_length_c 12.011(2)
_cell_angle_beta 96.23(1)
_cell_angle_alpha 92.14(2)
_cell_angle_gamma 113.06(1)
_cell_volume 851.515
_cell_space_diagonal_longest 14.431
Figure 1. Some sample non-looped data in a CIF.
Note that, although the data are laid out in a fairly neat fashion, this is not required by the CIF rules. So long as each entry is separated from the others by any white space (space, tab or end-of-line characters), the integrity of the file is maintained. Nevertheless, neat formatting aids visual inspection of the file contents, and is a style to be encouraged. The order of entries is irrelevant. Thus, while one might expect the beta value to appear between the values of alpha and gamma, this is not essential. The data names, or keys, are chosen to be fairly self-explanatory. However, their precise meaning is recorded in an external document, known as the CIF Core Dictionary (Hall, Allen & Brown, 1991), and the units and other conventions that apply to the particular data name are listed in the Dictionary. The last entry, referring to the space diagonal of the cell, is not a recognised data name in the CIF Core Dictionary. Nevertheless, it is legitimate to include it in the file as a local data item, which only specific applications will recognise. Note, though, that the construction of the data name is intended to indicate its nature.
The second example (Figure 2) shows a looped data structure. It is convenient to collect together repetitive and related data into a multi-dimensional array. The example illustrates how the position coordinates and equivalent isotropic U values of atoms in a cell might be represented in a CIF.
loop_
_atom_site_label
_atom_site_fract_x
_atom_site_fract_y
_atom_site_fract_z
_atom_site_U_iso_or_equiv
# Atom label x y z U_eq
C(1) .3559(3) .9938(3) .0315(2) .051(1)
C(2) .5131(2) 1.0377(2) .1012(2) .042(1)
C(11) .2095(4) 1.0428(5) -.1319(3) .098(2)
C(12) .5039(4) 1.2471(5) -.0916(3) .113(2)
O(1) .2294(2) .8641(2) .0590(2) .074(1)
O(2) .5957(2) .9710(2) .0337(1) .055(1)
N(1) .3602(3) 1.0927(3) -.0591(2) .066(1)
H2 .590(2) 1.158(2) .110(2) ?
H(O2) .717(5) 1.066(5) .037(3) ?
H111 .212 .982 -.217 ?
H112 .123 .985 -.082 ?
H113 .208 1.144 -.158 ?
H121 .600 1.217 -.099 ?
H122 .491 1.284 -.178 ?
H123 .547 1.343 -.019 ?
Figure 2. Some sample looped data in a CIF.
CIF SYNTAX
We have already covered the syntax employed in CIFs by example. Here a more formal summary of the rules is presented, which includes some details we have not yet considered.
1. A text string is a string of printable ASCII characters bounded by blanks, matching single quotes (') or double quotes ("), or (if the string extends over several physical records) by a semicolon as the first character of the first and trailing lines.
2. A data name is a text string starting with an underline (_) character.
3. A data item is a text string not starting with an underline, but preceded by a data name to identify it.
4. A data loop is a list of data names, preceded by `loop_' and followed by a list of data items.
5. A data block is a collection of data names (looped or not) and data items preceded by a data_xxxx code record (the xxxx represents an arbitrary text string). A data name must be unique within a data block. A data block is terminated by another data_ statement or by the end of file.
6. A data file is a collection of data blocks. The block codes must be unique within a data file.
7. A hash character (#) introduces a comment - all further text to the end of a line may be ignored.
These rules are a large subset of the syntax rules governing Self-Defining Text Archive and Retrieval (STAR) files, as described by Hall (1991). The Crystallographic Information File is a particular application of STAR, with some additional restrictions to facilitate crystallographic use. These are:
1. Lines must not exceed 80 characters in length.
2. Data names and block codes may not exceed 32 characters in length, and should be treated as case-insensitive.
3. Data items are recognised as being of number or character type. A text string that is more than 80 characters long, and so extends over more than one line, is of type text, which may be regarded as a subset of the character type.
4. A data item is of type number if it starts with a digit, plus, minus or period [0-9+-.].
5. A number may be given in integer, floating-point or scientific notation. A trailing integer within parentheses is understood to be the estimated standard deviation in the final digit(s) of the number.
6. A data item is of type text if it extends over more than one line. Semicolons as the first character of the first and last lines bound the data.
7. A data item is of type character if it is not a number or text.
8. Only one level of loop_ is permitted. Nested loops must be stored as lists within a text field.
9. Numeric data with physical significance have a default unit stated in the CIF Dictionary. Some alternative units are permitted for certain data items. The indexing data name then has a units extension as specified in the CIF Dictionary.
The complete description of the CIF syntax, with many examples, and the CIF Core Dictionary, is presented in the paper by Hall, Allen & Brown (1991).
CIF: A STANDARD FOR PORTABILITY
We began our discussion of the requirements for a data transfer standard by looking at three levels of portability --- between machines, between similar applications, and across diverse applications. We now present examples of how CIF or other STAR-type archive files are being used for all these purposes (we use the term CIF to refer specifically to files containing data names defined in the Core Dictionary).
1. Portability between machines.
The program system Xtal (Hall & Stewart, 1990) employs a binary data file for its data manipulation. As discussed previously, such files are not portable between different machines. In addition, Xtal performs input/output operations through a memory buffer, whose size is determined at installation and which affects the file structure, and so binary archive files are not guaranteed to be portable even between the same types of machine. The program can therefore dump an ASCII image of its binary data files in STAR format, through the routine CIFIO (Hall, 1990). Figure 3 shows an extract from such a file. Because it is designed specifically for machine-to-machine transfer, the layout is reasonably compact, and the data names (which are all purely local data designators) are not self-explanatory.
###################### XTAL Archive File in STAR Format #######################
data_p6122
_hist
;
STARTX 19/ 4/91 15:25:23ADDREF 19/ 4/91 15:25:24SORTRF 19/ 4/91 15:25:25
ADDATM 19/ 4/91 15:25:26FC 19/ 4/91 15:25:26CRYLSQ 19/ 4/91 15:25:29
CRYLSQ 19/ 4/91 15:25:30GENEV 19/ 4/91 15:25:51GENTAN 19/ 4/91 15:26: 8
BONDLA 19/ 4/91 15:26:11
;
_labl
;
19/ 4/91 15:25:23
Test case from Larson -- dummy P6122 structure.
;
loop_
_cell_pak_1
.8530000+01 .8530000+01 .2037000+02 .0000000+00 .0000000+00 -.5000001+00
.2500000+00 .2500000+00 .3333334+00
loop_
_cell_pak_2
.1000000-01 .1000000-01 .1000000-01 .1745329-03 .1745329-03 .1511499-03
.2777778-04 .2777778-04 .2777778-04
loop_
_cell_pak_3
.1353694+00 .1353694+00 .4909180-01 .0000000+00 .0000000+00 .5000001+00
.2500000+00 .2500000+00 .1666667+00
_symm_pak_1_1_lattice_type 1
_symm_pak_1_2_centro_type 1
_symm_pak_1_3_total_symops 12
_symm_pak_1_4_basis_symops 12
_symm_pak_1_5_equiv_symops 2
_symm_pak_1_6_multiplicity 1
_symm_pak_1_7_cedar_symops 0
_symm_pak_1_8_moles/cell 24
_symm_pak_1_9_cryst_system 7
_symm_pak_1_10 0
_symm_pak_1_11 0
_symm_pak_1_12 0
loop_
_symm_r11 _symm_r21 _symm_r31 _symm_r12 _symm_r22 _symm_r32
_symm_r13 _symm_r23 _symm_r33 _symm_t1 _symm_t2 _symm_t3
1 0 0 0 1 0 0 0 1 .000000 .000000 .000000
-1 0 0 0 -1 0 0 0 1 .000000 .000000 .500000
0 -1 0 -1 0 0 0 0 -1 .000000 .000000 .833333
0 1 0 1 0 0 0 0 -1 .000000 .000000 .333333
1 0 0 -1 -1 0 0 0 -1 .000000 .000000 .000000
-1 0 0 1 1 0 0 0 -1 .000000 .000000 .500000
1 1 0 0 -1 0 0 0 -1 .000000 .000000 .166667
-1 -1 0 0 1 0 0 0 -1 .000000 .000000 .666667
0 1 0 -1 -1 0 0 0 1 .000000 .000000 .333333
0 -1 0 1 1 0 0 0 1 .000000 .000000 .833333
1 1 0 -1 0 0 0 0 1 .000000 .000000 .166667
-1 -1 0 1 0 0 0 0 1 .000000 .000000 .666667
_sgnm_pak_1 P_61_2___(0_0_-1)
Figure 3. Xtal archive file in STAR format.
Nevertheless, the file may still be manually altered with a text editor, if the need should arise. Further, it is able to be sent by e-mail to a different site, where a different Xtal implementation may read it to generate a binary work file in the local machine's native format.
2. Portability between similar applications
A more general use for CIF is the ability to supply the same information to different crystallographic programs. At the Editorial Office of Acta Crystallographica, we have over the past couple of years developed procedures for checking the accuracy and consistency of numeric values reported in submitted structural papers. The data that need to be checked have been stored in CIFs, from which the subset of data required by each individual checking program is easily extracted. Currently we use programs that have been available to the crystallographic community for some years; as yet, these do not read CIFs directly, and so translation routines are required to input the
data to each program. It is expected, however, that upgrades to these programs will gradually come to incorporate CIF readers. In any case, the early use of CIF as a front end to the checking procedure has meant that we are now able to check the data in author-supplied CIFs using exactly the same methods developed for purely in-house use.
Figure 4 is a graphical representation of a directory containing work files during the checking of a structure in Chester. All the input files (represented by icons depicting stacks of punched cards!) are generated
automatically from the CIF (represented by a crystal icon). The CIF named `STARIN' is the parent file; that named `STAROT' contains just the subset of the data required for checking.
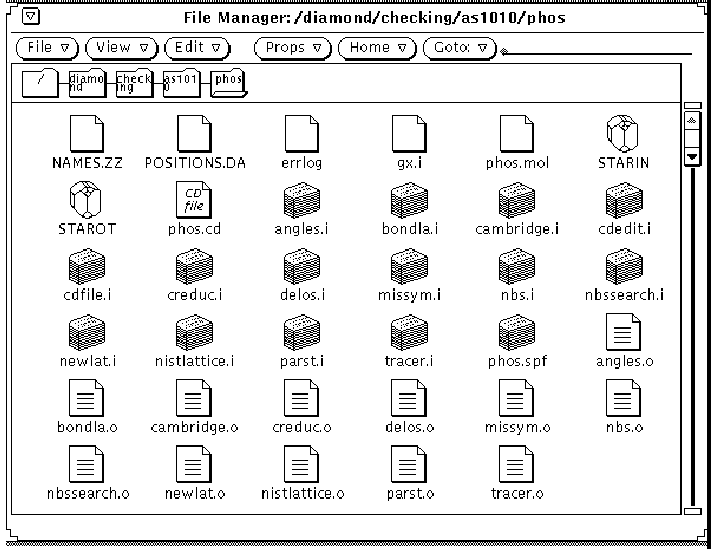
Figure 4. Work files derived from a CIF for structure checking in Chester.
Because CIF is a new standard, relatively few programs are yet able to make full use of CIF-based I/O. Nevertheless, a growing number of packages can generate and/or read such files, and it is likely that before long the output from a structure solution program may be fed into an unrelated refinement program via an intermediate CIF. Some applications already known to support CIF are: Xtal3.0 (Hall & Stewart, 1990), which can read and write CIFs conforming to the Core Dictionary, as well as its own STAR-based dump file; SHELX92 (Sheldrick, 1992); PLATON92 (Spek, 1992); TEXSAN (Molecular Structure Corporation, 1992); and DIFRAC (Flack, Blanc & Schwarzenbach, 1992), which converts single-crystal diffractometer output files from various sources to CIF format.
It is clear that there is a rapidly expanding base for data interchange via this new standard.
3. Portability to different applications
In some respects, the most interesting outcome of the development work on CIF is the discovery that it is feasible to process such a file to generate galley proofs of a journal paper without compromising its ability to convey data between other computer programs. The program ciftex (McMahon, 1992) will translate a CIF into a TeX file. TeX (Knuth, 1984) is a typesetting control language that allows high-quality output to be generated from laser printers or high-resolution phototypesetting equipment.
Much of the numeric and experimental information contained in a typical Acta structural paper is, or can be, expressed in a tabular or columnar layout. Ciftex can retrieve specific data items, and embed them in TeX commands to specify their layout on the printed page. Specific data fields have been devised to include the running text of a paper, so that the entire discussion of a structure can be laid out in the _publ_section_comment field. Other items of information, such as the authors' names and addresses, are given in the CIF within specific fields. This allows the file to be searched on authors' names by database techniques; yet the ciftex translator can extract the names and addresses and concatenate them in the traditional layout of the journal.
Because the translator maps CIF data names to different pieces of TeX code selectable at run time, the ciftex process is very flexible. It was used to typeset the CIF Dictionary section of the Hall, Allen & Brown (1991) paper direct from the master dictionary file, which is itself in STAR format. It is also planned to use it for typesetting the next edition of the World Directory of Crystallographers, which will also be constructed as a STAR file.
Figure 5 is a very brief extract from a CIF submitted for publication to Acta Crystallographica, Section C. Figure 6 shows part of the TeX file produced by the ciftex translator, and Figure 7 shows the result of processing this file. For the majority of structural papers submitted to Acta, this process is fast (typically occupying less than a minute of real time), and efficient. Intervention by editorial staff is often minimal; and it is just this question of efficiency that has previously been a barrier to publishers' willingness to accept computer-ready submissions from authors.
The Acta Editorial office is now also in a position to consider devlopments of online representation of journal papers. From an archival CIF that may contain more information than is usually published in a journal paper, the computer user may select any of the data included, and have a journal-quality paper typeset on screen, or printed on a local laser printer.
>data_9109ITH
_publ_contact_author
;
Dr. Kentaro Yamaguchi, School of Pharmaceutical Sciences
Showa University, 1-5-8 Hatanodai, Shinagawa-ku, Tokyo 142, Japan
;
_publ_contact_author_email ?
_publ_contact_author_fax '03 3784 8296'
_publ_contact_letter
;
Please consider this submission for publication in Acta
Crystallographica C. Associated hard-copy materials are
attached with this diskette.
;
_publ_requested_coeditor_name 'Prof. T. Ashida'
_publ_requested_journal 'Acta Crystallographica C'
#------------------------------------------------------------
_publ_section_title
;
2-Methyl-4,6-diphenyl-1,2,3-triazinium Iodide
;
loop_
_publ_author_name
_publ_author_address
'Kentaro Yamaguchi'
; School of Pharmaceutical Sciences, Showa University
1-5-8 Hatanodai, Shinagawa-ku, Tokyo 142, Japan
;
'Takashi Itoh'
; School of Pharmaceutical Sciences, Showa University
1-5-8 Hatanodai, Shinagawa-ku, Tokyo 142, Japan
;
'Mamiko Okada'
; School of Pharmaceutical Sciences, Showa University
1-5-8 Hatanodai, Shinagawa-ku, Tokyo 142, Japan
;
'Akio Ohsawa'
; School of Pharmaceutical Sciences, Showa University
1-5-8 Hatanodai, Shinagawa-ku, Tokyo 142, Japan
;
_publ_section_abstract
;
The planarity and endocyclic bond distances of the 1,2,3-triazine
ring indicate extensive delocalization of electron density.
The triazine ring and the iodine anion lie
on the crystallographic twofold rotation axis. The bond angle
involving the three N atoms is very large
[129.0(6)\%] because of the ionic contribution of the central
N^+^ atom, which acts as a counterion to I^-^.
;
_publ_section_comment
;
We are interested in the chemistry of heterocyclic compounds containing many N
atoms. An X-ray analysis of the title compound (1) was undertaken to
investigate the structure of 1,2,3-triazinium salts and provide information for
theoretical studies of this class of compounds. The preparation of compound
(1) was reported by Ohsawa, Arai, Ohnishi, Kaihoh, Itoh, Yamaguchi, Igeta
& Iitaka (1985).
The triazine ring is almost planar, with a maximum displacement from the
least-squares plane of 0.013\%A for N5. This planarity as well as the
endocyclic bond distances indicate an extensive delocalization of electron
density. . . .
;Figure 5. Extract from a CIF submission to Acta Cryst., Section C. Some typesetting codes (\w for Greek omega, ^..^ for superscripts) appear; these are described in the CIF Dictionary paper.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% TeX output generated via IUCr CIF-to-TeX convertor version 1.04
% at 14:49 23 Apr 1992
% Copyright (c) 1992 International Union of Crystallography
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\newif\ifproof \prooftrue \newif\ifexphead \expheadtrue
\input /usr/local/lib/cif/actacif.tex
\ifproof\else\input /usr/local/lib/cif/header.actac\fi
\ifproof\else\let\sevenpoint=\tenpoint\let\ninepoint=\tenpoint\fi
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\newif\iftwocol\twocolfalse
\abovedisplayskip=0pt\belowdisplayskip=0pt\frenchspacing
\noindent
{\tenit Acta Cryst.\/ }{\tenrm(1992). C{\tenbf48}, 000--000}\par
\vskip10pt \tolerance=5000
\def\structI{9109ITH}
\global\let\datablock=\structI \newdblock
\coedno{AS1000}
\begingroup\raggedright\baselineskip=14pt\title{2--Methyl-4,6-diphenyl-1,2,3-
triazinium Iodide
}
\author{ Kentaro Yamaguchi, Takashi Itoh, Mamiko Okada, Akio Ohsawa}
\address{School of Pharmaceutical Sciences, Showa University, 1-5-8 Hatanodai,
Shinagawa-ku, Tokyo 142, Japan}
\defaultfont
{\eightpoint\noindent (\it Received \rm 00 \it XXXX \rm 1992;
\it accepted \rm 00 \it XXXX \rm 1992)}
\abstract{The planarity and endocyclic bond distances of the 1,2,3-triazine
ring indicate extensive delocalization of electron density. The triazine ring
and the iodine anion lie on the crystallographic twofold rotation axis.
The bond angle involving the three N atoms is very large
[129.0(6)$^\circ$] because of the ionic contribution of the central
N$^{+}$ atom, which acts as a counterion to I$^{-}$.
}
\comment{We are interested in the chemistry of heterocyclic compounds
containing many N atoms. An X-ray analysis of the title compound (1)
was undertaken to . . .
}
. . .
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% Table of bonds %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\medskip\noindent \parindent=0pt \leftskip=0pt plus1fil
\rightskip=0pt plus-1fil \parfillskip=0pt plus2fil
{\tenrm Table \tableno. }{\tenit Geometric parameters {\tenrm (\AA, $^\circ$)}
for {\tenrm \datablock}}\par
\begindoublecolumns\twocoltrue \sevenpoint \settabs 2 \columns
\+ {C2}---{N3} &\kX{1.469 (10)} & &\cr
\+ {N3}---{N5} &\kX{1.300 (4)} & &\cr
\+ {C4}---{C6} &\kX{1.378 (6)} & &\cr
\+ {N5}---{C6} &\kX{1.358 (6)} & &\cr
\+ {C7}---{C12} &\kX{1.392 (7)} & &\cr
\+ {C7}---{C8} &\kX{1.397 (7)} & &\cr
\+ {C7}---{C6} &\kX{1.461 (6)} & &\cr
\+ {C8}---{C9} &\kX{1.392 (7)} & &\crFigure 6. Extracts from the TeX file generated by ciftex from the CIF of Figure 5.
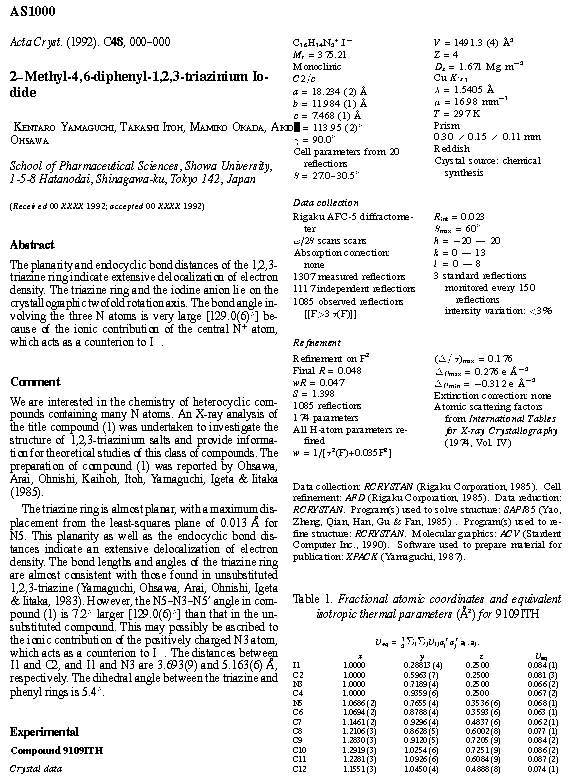
Figure 7. A typeset proof from the example of Figure 5.
We mentioned above the ability to search a CIF for, say, authors' names. The provision of many specific data fields allows such a file to be regarded as a well-partitioned database record. However, database applications are again most efficient where the files searched have an efficient machine-specific structure. It is therefore unlikely that CIFs by themselves will be used in a database format; but the translation of specific fields within the CIF to database record fields is straightforward, and so they have an immediate application as a database input mechanism. This approach is already being developed by the Cambridge Crystallographic Data Centre, who have a translation program, CIFER (Allen & Edgington, 1992), that converts CIF data to their native data storage format. Interest in this approach has also been exhibited by other database maintainers.
A TRUE STANDARD FOR THE FUTURE?
We have seen that CIF is already proving its worth as a data exchange standard. Many program authors are writing CIF parsers and generators; databases are planning to use it; and it allows a high level of automation in the publishing process. We may ask the question: is it the way forward?
There are certain respects in which it has clear limitations. First, it is a rather loose `standard'. Consider the 80-character line limit. It is not clear from the specification whether this includes the end-of-line delimiter characters (which, of course, differ between operating systems). Neither is it clear exactly what ASCII characters may appear in the file --- may the CTRL-L (formfeed) character be included? What about vertical tab? Further, the CIF Dictionary definitions, while detailed, are not exhaustive nor guaranteed free from error or misinterpretation.
Yet, the informality of the standard may be a point in its favour. True international standards specifications, as produced by ISO or national organisations like ANSI, are often so detailed and so strict as to be exceptionally difficult to implement. Furthermore, they may provide little scope for flexibility in handling cases not explicitly covered in the specification. As programming skills develop, programmers may prefer to apply fuzzy-logic techniques to handle data that is flexible (within known limits), rather than require only selected and precise inputs.
There are other limitations inherent in the file structure, such as the lack of support for nested loops, or internal indexing between different data blocks. But it must be recognised that CIF, as a tool for use in a specific scientific field, has fairly modest aspirations. It does not require the full power of the abstract data presentation protocol known as ASN.1 (Abstract Syntax Notation - 1) or of the document markup system SGML (Standard Generalized Markup Language). It is sufficiently powerful to fulfil most of the current needs of the crystallographic community. Furthermore, the CIF syntax embodies a simple parseable grammar, and can be formally considered a subset of more structured data representation mechanisms. Hence, it is amenable to upwards extension in the direction of such formal standards as and when the need arises.
Currently, working parties sponsored by the IUCr are considering extensions to the CIF Dictionary to include data items specific to powder diffraction and macromolecular studies. Other scientific bodies are exploring the possibilty of adopting CIF or extensions to CIF for their specific data archival purposes. It is likely that CIF will indeed become established as an important component in data exchange within crystallography and related disciplines in the years ahead.
REFERENCES
Allen, F. H. & Edgington, P. R. (1992). CIFER: a Program for CIF Generation. Crystallographic Data Centre, Cambridge, England.
Brown, I. D. (1983). Acta Cryst. A39, 216--224.
Flack, H. D., Blanc, E. & Schwarzenbach, D. (1992). J. Appl. Cryst. 25, in the press.
Hall, S. R. (1990). CIFIO: Xtal3.0 Crystallographic Program System, edited by S.R. Hall & J. M. Stewart. Univs. of Western Australia, Australia, and Maryland, USA.
Hall, S. R. (1991). J. Chem. Inf. Comput. Sci. 31, 326--333.
Hall, S. R., Allen, F. H. & Brown, I. D. (1991). Acta Cryst. A47, 655--685.
Hall, S. R. & Stewart, J. M. (1990). Editors. Xtal3.0 Reference Manual. Univs. of Western Australia, Australia, and Maryland, USA.
Knuth, D. E. (1984). The TeXbook. Reading, MA: Addison-Wesley.
McMahon, B. (1992). CIFTEX. A Filter for Translating a Crystallographic Information File to a TeX File. IUCr, 5 Abbey Square, Chester, England.
Molecular Structure Corporation (1992). TEXSAN. Structure Analysis Package. MSC, 3200A Research Forest Drive, The Woodlands, TX77381, USA.
Sheldrick, G. M. (1992). SHELX92. A system for crystal structure solution and refinement. Univ. of Gottingen, Germany.
Spek, A. L. (1992). PLATON92. A Multipurpose Crystallographic Tool. Univ. of Utrecht, The Netherlands.
Copyright © 1997 International Union of Crystallography
IUCr Webmaster